Delta to Redshift Spectrum Connector
Context
At Goibibo, we are heavy AWS Redshift users. Now, Redshift has served us very well over the years, but it’s definitely not suitable for all use-cases. Specifically, it’s not meant to be used as a data lake, but our production Redshift cluster had morphed into a data lake over the years. Redshift is not very suitable as a data lake, and you cannot scale it up without downtime. So we decided to migrate some data away from Redshift, and keep it in S3. There are two things to consider when building a data lake:
- How to ingest data into the data lake,
- How to query data in the data lake.
Queries
The query engine was an easy choice for us: Redshift Spectrum. Redshift Spectrum provides us a way to query data kept on S3, and reuses some of Redshift’s infrastructure. Spectrum’s SQL dialect, is also very similar to Redshift’s dialect, so it was easy for our analysts to use.
This is important to us, because at Goibibo, we have lots of analysts, and thousands of pre-existing queries, lots of them pretty hefty queries, that would be tough to migrate to a different SQL dialect. This consideration also ruled out AWS Athena. Spectrum isn’t perfect, especially with nested data, but it was the best compromise for us. And so we started using Spectrum.
Ingestion
We pointed our existing ingestion jobs(written in Spark) to S3 instead of Redshift. This worked, however, S3 is not a database, and by itself, it doesn’t have any ACID guarantees. Some of our critical jobs, which affect our company finances, depend on the consistency of data in our data lake, so ACID was important for us.
This is where Databricks Delta came in. Delta provides ACID guarantees on top of S3, building MVCC-like features on top of a log of transactions, which is called the DeltaLog. While there’s some value to the argument that we should either stick to either Redshift or Databricks for all our query needs, given our requirements, it wasn’t immediately feasible. So we set about building a Delta-Spectrum connector:
Delta
Files in Delta are just parquet files, and meta-data is stored in the DeltaLog, which is just a collection of json files stored in a S3 subdirectory. The DeltaLog contains an ordered collection of all transactions on the Delta Table, and also keeps tracks of meta-data such as operation type, partitions changed, files changed, alongside min-max statistics. For efficiency, there are also regular snapshots of the DeltaLog, which is stored in parquet format.
Since Delta stores the data itself in parquet format, Spectrum can also immediately query this data. However there’s a catch: Delta doesn’t delete old files when it is deleting or updating data, instead it updates its metadata in the DeltaLog. If we query this data through Delta, it reads the data and ensures that only the correct files are queried. Spectrum itself doesn’t have a clue.
RedShift Spectrum Manifest Files
Apart from accepting a path as a table/partition location, Spectrum can also accept a manifest file as a location. This manifest file contains the list of files in the table/partition along with metadata such as file-size. Our aim here is to read the DeltaLog, update the manifest file, and do this every time we write to the Delta Table.
Note that Databricks’ Athena connector does the same thing, however Athena and Spectrum do not have the same manifest file formats, so you cannot have an external table that you can query both via Spectrum and Athena. One workaround is to create different external tables for Spectrum and Athena.
As of now, Databricks Delta doesn’t have stable APIs for reading or manipulating the DeltaLog. But at its heart, the DeltaLog is just a collection of json files, so it’s easy to read and parse:
The Connector
Our DeltaToGlue (as we’re calling it) connector, has had two major versions till now. The first version was fairly simple. It used to read a list of files from the DeltaLog, generated a manifest file and then updated the table location in the AWS Glue Data Catalog, to point to this manifest file.
This worked only for unpartitioned tables, as partitions need to have separate manifest files of their own.
Then we added partitioned-table support, and started pointing all the partitions to their manifest files individually. Typically, however, a single write on a table affects only a few partitions. Our approach was fairly inefficient because it wrote manifests for all partitions, even if only a few partitions had changed.
We looked at the information that DeltaLog provides, and we found that it stores partition values, along with the files written in those partitions, alongside each write transaction. In the catalog’s table properties, DeltaToGlue stores the Delta version of the table for which it was last run. On a subsequent run, DeltaToGlue then figures out the partitions which have seen an update, and goes and updates the partition manifest files for only those partitions! Much more efficient.
Performance
We saw a huge increase in performance of queries on Spectrum, after moving to Delta. Much of this can be attributed to the OPTIMIZE function that Delta provides, which merges small parquet files written by scheduled batch jobs, into a bigger file that is more query-friendly. Delta manages to do this while maintaining consistency! Here are some before and after figures for a sample query:
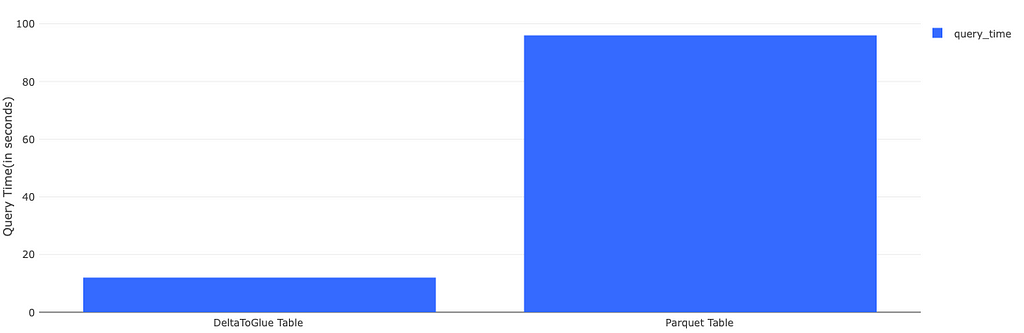
The left table shows the query results for a table we already had in Spectrum before we moved to Delta. The right table is a Delta Table for the same data. There are no differences between the tables, except that the Delta Tables are optimized(but not by z-order). This isn’t a very scientific test, but we saw roughly the same performance by repeating queries(the size of the table seems to have prevented caching!), and a similar speedup in most read queries.
What’s next:
At the moment, we run deltaToGlue after each write manually in our code. Ideally, we’d like to hook into Spark to do it automatically. Spark 3, not yet released as of the date of writing this post, should help by allowing custom spark catalogs. Not only would that simplify all our AWS Glue specific code by having a inbuilt Glue Catalog implementation in Spark, it would also allow for custom-built dual catalogs, that can update Spark, Spectrum or Athena tables, all in one go.
Usage Example:
Links:
Delta-Spectrum Connector was originally published in Backstage on Medium, where people are continuing the conversation by highlighting and responding to this story.