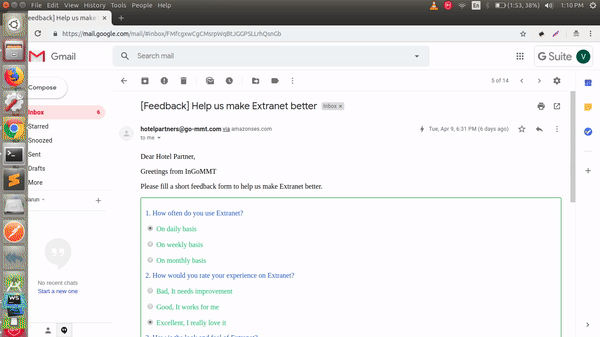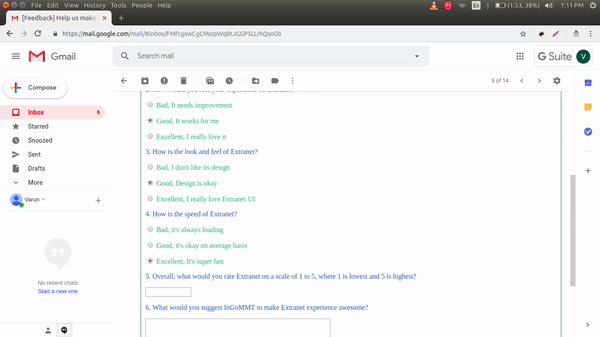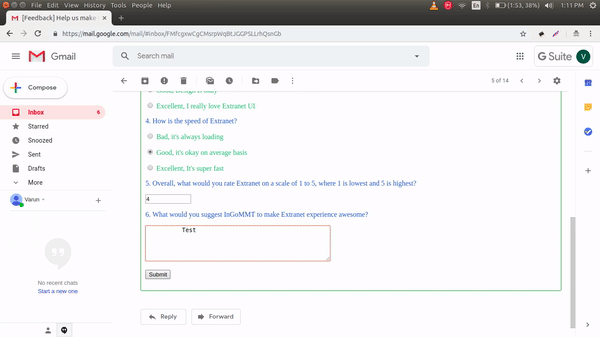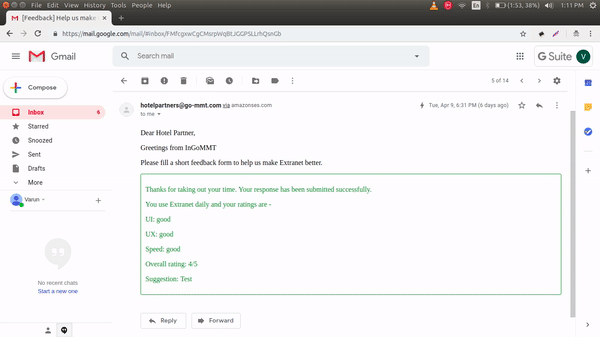
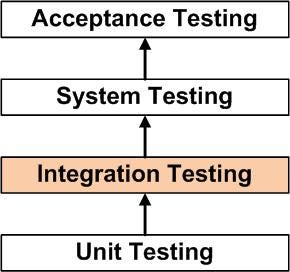
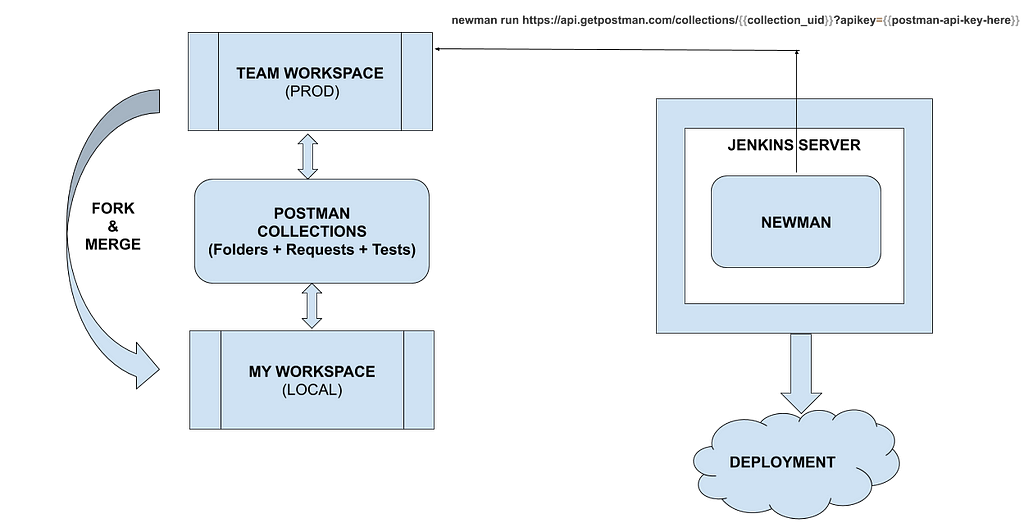
“Gia” is Goibibo’s 24 X 7 travel assistant, capable of handling nearly 300 types of queries on travel bookings done on Goibibo. Click here to read more about what Gia can do.
Building any chatbot is very easy because the technology is easily available. But building a chatbot that solves a particular business problem takes time and dedicated effort. The sooner you identify those areas, the faster you can make your bot effective.
In this article we want to share 3 key learnings that helped us in identifying focus areas to improve the user experience on Gia. We hope this helps anyone building a chatbot.
Learning #1: 360 degree learning is essential to understand user behavior
This is a timeless tenet for product folks and most of you might understand it well. So instead of belabouring the obvious, let me give you some examples. When we say 360 Degree Learning, it means picking up signals from anywhere — data, qualitative feedback and interaction design.
Learning from Data

Here was the problem — every week our engineers would build new use cases and release them. But our data was telling us that users weren’t really using them because they just didn’t know about it. And if we didn’t build those use cases, Gia would never be able to answer a variety of questions. Oops, problem.
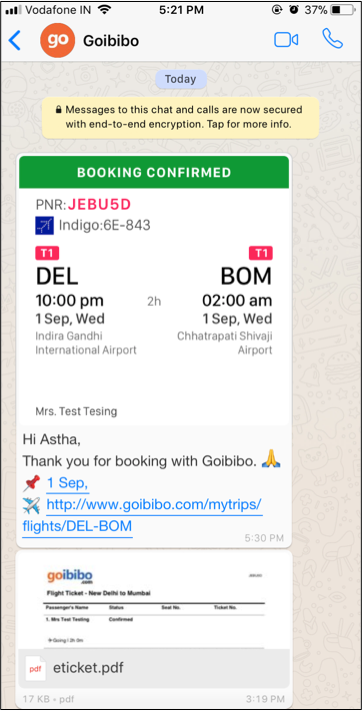
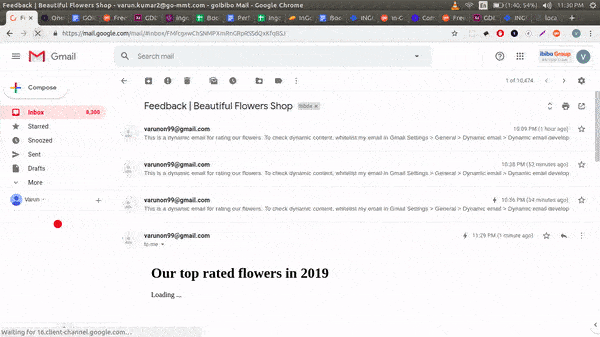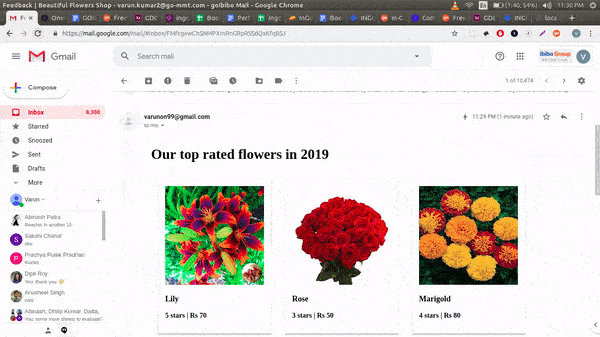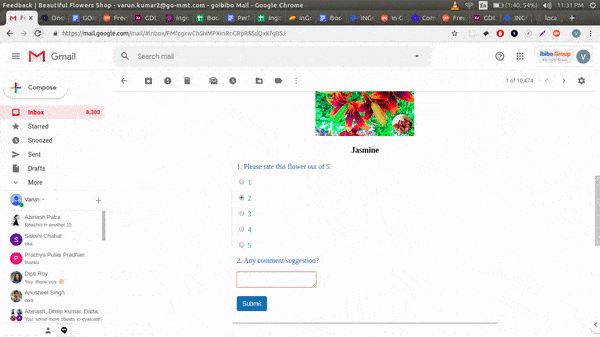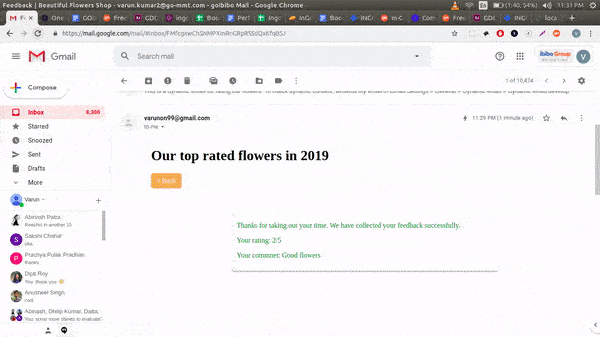
Talking to a chatbot is a lot of like ordering food in a restaurant. Unless you know what the restaurant serves you won’t be able to order. We never walk in and ask for the first food item that comes to our mind. We look at the menu and then order what we want, right? So we needed to build an interface that allowed for this.
The image shows how this looks. With this design, we started observing that discovery of hidden uses started happening
Here is a a second example of where learnt from data. Suddenly, one fine day, we started observing a lot of customers talking directly to human agents — bypassing Gia. We suddenly had big problem on agent staffing. This was surprising to us because nothing had changed on the system to trigger this.
It turned out that a section of users had figured out a way to directly talk to agents by saying “I want to talk to an agent”. They figured out this loophole. Users are smart!
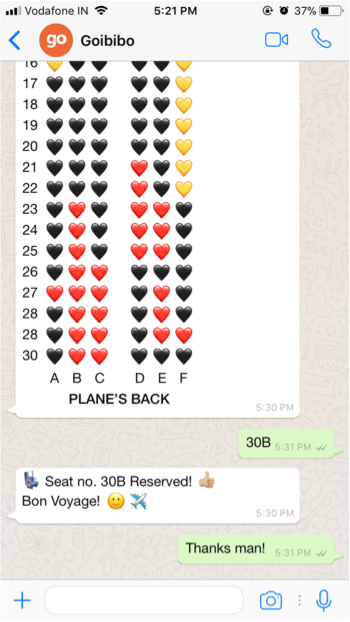
Based on this observation we quickly, enforced a policy that enforced every question to be answered by Gia before being handed to a human agent.
It was a tough call because we also had to introspect on why these users felt the need to bypass talking to Gia. But we didn’t let that learning come in the way of fixing this problem.
Learn from Qualitative Signals

We Indians are polyglots. Most of us find it natural to keep transitioning between English and our mother tongue at will. This habit also exists when we type and we call it the “Vinglish Problem” — vernacular + English.
The image of the left shows an example of a user wanting to know her/his refund status by saying “mera refund kab ayega”. To the best of our knowledge, there is no publicly available dataset for handling this. One of the ways we attempted to fix this is by having a dedicated team which does the priceless job of mapping user messages with what Gia can understand. The taggers can map a vinglish message to what Gia can understand. We don’t claim to have cracked this and are investing in NLP to solve this better.

A second example of learning from qualitative sources is how we rode on an existing WhatsApp paradigm to handle cases when Gia took time to respond. Most of us are habituated to seeing the two blue ticks on WhatsApp and then wait for the typing indicator from the other person.
When we noticed high latency in serving responses in certain cases, we figured using the same paradigm made sense. Of course, we fixed the original source of high latency. But it always helps to have a fallback.
The familiar paradigm for such cases is to show a loader. But on a conversational interface, this approach works for us. It certainly helps if you are using a paradigm that WhatsApp already has established with 300+ million Indian users!
Learn from Design

When our team set out to understand chat interaction paradigms, they came up with an interesting insight. Based on experiments and field visits, we learnt that when presented with a conversational interface users tended to primarily see from top to bottom only.
Usage of horizontal scrolls & bottom-to-top processing was limited. Admitted, these could materially vary for a different user base and for different use cases. But since this was our learning, we have started moving away most other interaction paradigms. This manifested in a major design change for Gia.
We hope the above examples helped you understand how it is important to use every resource available to you to learn and incorporate those learnings. We are just getting started on this journey and future is certainly learning rich.
Learning #2: Figuring out when and how to blend the human agent experience inside Gia
I’m sure I don’t need to explain that Artificial Intelligence (and its sub-discipline Natural Language Processing) isn’t going to work always. In almost all applications there is a strong business case to have a human agent taking over when things don’t go to plan. In the case of Gia as well, we have human chat agents who can continue a conversation and get the issue resolved for our users. But when should the agent come into the picture?
Introducing the Human Agent
While it is possible to automatically invoke human assistance, Gia currently makes this decision on the basis of per-defined end points. Here is an example —

In this case, the conversation was assigned to a human agent when the user indicated that she/he was not happy with the response for a query about refund status. This fires a pr-configured rule that transfers the chat to an agent.
Gia also makes it a point to tell the user that he/she is now chatting with a Support Executive and not Gia.
The decision on when to do this depends on the following scenarios —
- Identifying cases when the bot is able to understand the user message & the response is programmable but hasn’t been done yet. We call this as the “Missing Use Case” problem.
- Identifying cases when the bot is able to understand the user message but the response can’t be programed because of any reasons (like an external dependency or urgency, etc.).
- Identifying when the bot is not able to understand the user message. We call this as the “Missing Intent” problem. This is needed because we are a talkative lot and the list of things we can say could be range from sharing forwards to Good Morning messages and even the odd expressions of love for Gia :)
Setting up with Human Agent for Success
In order to build a chatbot at scale and solving a critical business problem, it is equally important to set the agents up for success. This starts with measuring customer happiness using the interaction. An example of this is shown below —

These responses act as a way to improve the quality of agent conversations over time.
Finally, keep in mind that a bot has accustomed the user to real time responses. So when you transfer the chat to an agent, then it becomes important to reset expectations on how soon you will be able to give a response. The first response time of the human agent is critical to prevent user frustration.
Learning #3: Achieving success requires team work.
We have probably saved the best for the last! In order to achieve lasting customer success it is important to have multiple teams come together. From our experience it is imperative that the following 5 teams come together to make Gia success. These are mentioned in the table below.
Here is a simple representation of what would happen even if one of the teams was not involved.

What does user validation look like?
Along every step of the journey we were making choices that we felt were in the best interest of the user. But the strongest sign of validation from users was when we started observing repeat users of Gia (across many months and multiple transactions) look like this!

Of the users who talk to Gia on a daily basis the proportion of users who have already spoken to Gia in the past rose by nearly 4X! So users who tried speaking to Gia, liked her enough to keep coming back with a new query every time they traveled or had a new trip!
Closing thoughts

If you are still on the fence on whether to do a chatbot, then think no longer. This trend was the strongest validation we’ve seen that users are ready for a conversation experience. You just need to figure out how to make it work for your business!
As a final takeaway, we’d like to repeat the message with which we started this post.
Building any chatbot is very easy because the technology is easily available. But building a chatbot that solves a particular business problem takes time and dedicated effort. The sooner you identify those areas, the faster you can make your bot effective.
3 Things We Learnt From Building Gia was originally published in Backstage on Medium, where people are continuing the conversation by highlighting and responding to this story.